Форум поддержи Rush Analytics - напишите нам и мы обязательно поможем!

 Чекалка позиций и SSL
Чекалка позиций и SSL
При смене протокола в настройке чекалки позиций - система не дифференцирует http и https протоколы.
Проще говоря - не работает съем позиций сайтов на secure protocol, если до этого стоял обычный http.

 перегруппировка с другой точностью
перегруппировка с другой точностью
Здравствуйте!
Подскажите, почему же нет возможности перегруппировки с другой точностью?
(один из вариантов "зачем" -- как у нас, тупо забыли прочекать остальные точности)
Помнится я уже задавал подобный вопрос про перманентное хранение серпов. Это было уже год назад... Да, там вопрос иной был, но тоже упирался только в перезапуск проекта по старым серпам(и частично по новым).

как кластеризовать ключевые слова
Добрый день. Нужна ваша помощь.
Мне нужно кластеризовать ключевые слова по признаку.
На данный момент 2 попытки привели к провалу )) - 540 рублей.
Из мануала я не понял как сделать. буду рад вашим подсказкам.
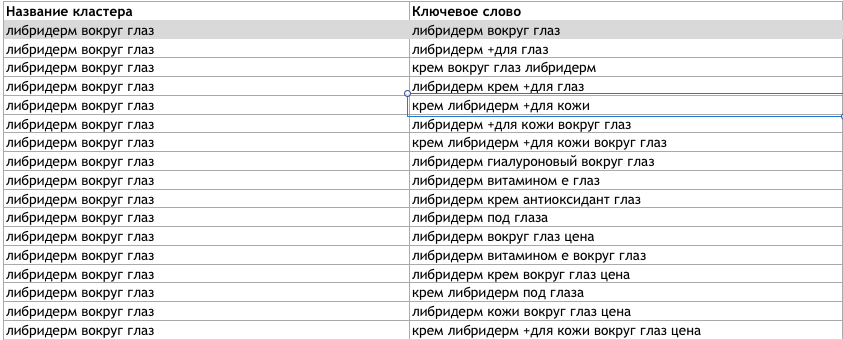
Мне нужно, что бы все где упоминаюстя лицо, кожа, глаза, ноги и пр. - это были отдельные кластеры? И они не смешивались между собой?
пример в картинке №1
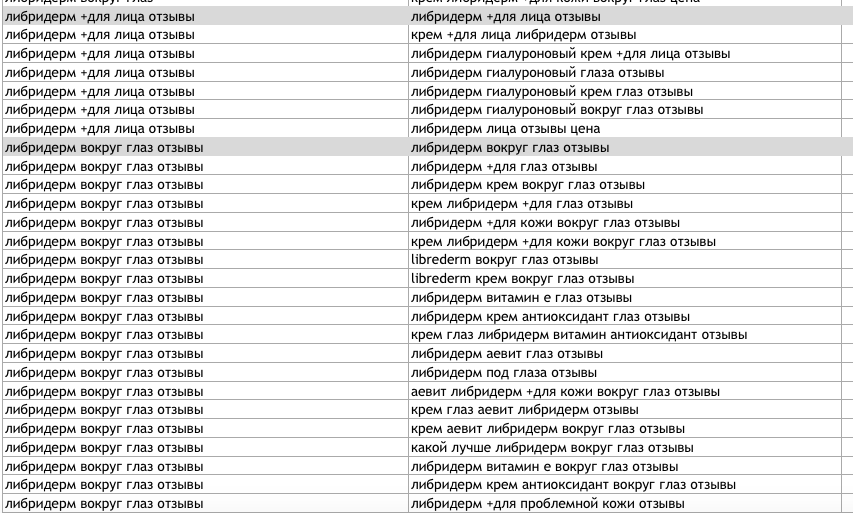
Так же мне не нужно, чтобы кластеризовались с определенными занчениями, например слово отзывы
Пример в картинке №2
Подскажите как этого добиться?
 все точности в одном файле и докластеризация
все точности в одном файле и докластеризация
Суть докластеризации повторять не буду, всё слово-в-слово уже описывали здесь:
http://rushanalytics.userecho.com/topics/104-klasterizatsiya-s-mnozhestvennyim-shagom/
Про все точности в одном файле вопрос уже тоже задавали, но так и не смогли объяснить как это можно представить, а Вы так и не подумали на эту тему.
Попробую объяснить, как действительно удобно было бы видеть готовый результат кластеризации, причем с возрастанием/убыванием точности кластеризации:
==================================================
ПРИМЕР ВАШЕГО КОНКУРЕНТА (J***-Mag**.org)
группы grp2-4 нумеруются по аналогии с grp1. Т.е. самая большая grp2 получает номер 1. Поменьше — номер 2. Аналогично grp3 и grp4.
spec-grp — так называемая «тематическая группировка». Это очень широкое объединение групп из столбца grp1. Создана для ускорения фильтрации/разбора больших ядер. Также хорошо разделяет омонимию (виза в грецию/виза или мастеркард/виза начальника).
==================================================
Сейчас у меня возникла такая ситуация,
решил сделать кластеризацию,
выбрал точность 8, остальные забыл отметить,
результат не устроил,
как же теперь мне "уменьшить" точность?
да, даже если ставить все точности сразу,
то сопоставление человеку делать очень долго и сложно.
например, для одного СЯ:
для одной группы запросов нужна высокая точность, т.е. разбить как можно сильнее по группам,
а для другой группы видно, что можно менее сильно разбивать.
Вот это всё легко делать на одной странице, как в приведённом примере.
PS: извините, пожалуйста, за пример конкурента, но мне более лучше придумать чем у них не представляется, такое представление группировки - для семантика просто находка.

Переработка страницы "Съем позиций - Настройки проекта"
1. http://shot.qip.ru/00r78b-3DKMgB7HM/ вот эти вот пункты нужно перевести на аякс технологию, чтобы странница каждый раз не перезагружалась.
На эту перезагрузку тратится куча времени.
Приходится каждый раз скролить сверху вниз.
Знаю что группы можно файликом настраивать, но качественно реализованное дублирование не помешает.
2. Добавить для заголовков http://shot.qip.ru/00r78b-5DKMgB7HQ/ возможность сворачивать содержимое. Обозначить пунктиром или стрелочкой.
у меня пропал проект( что делать?
Был запущен проект nordichome. Сняли 42р со счета за запуск, проект сначала не двигался, а потом просто пропал!!! Как его теперь найти??
Проверка ключевых слов - нужна/ожидается операция со строками, а не с ячейками данных.
Проверка ключевых слов - нужна/ожидается операция со строками, а не с ячейками данных.
СЕЙЧАС
ввод:
загружаем из файла данные в двух столбцах: слова и частотка
вывод:
получаем файл с данными в одном столбце, т.е. без частотки...
ОЖИДАЕТСЯ
ввод:
загружаем из файла данные в двух столбцах: слова и частотка
вывод:
получаем файл с данными так же в двух столбцах.
Максимальная универсальность данного инструмента была достигнута,
при опреации перемещения/распределения плохой/хороший по разным листам - оперируя всей строкой. Т.к. юзер может загрузить файл с данными не только с двумя столбцами, а с 3-4мя. Конечно, способ пусть выбирают прогеры, что будет легче/быстрее - сопоставление результирующих данных с исходными или операция со строками.
==================================================
Пользуясь случаем)), хотел спросить про данный инструмент:
если не секрет, то хотя бы несколько слов, про то по какому принципу происходит определение плохой/хороший ключ?
Мне как технарю, уж очень не по себе доверять абсолютно закрытым алгоритмам.
Я понимаю, что Вы не фигню какую нить настряпали)),
во первых я Вам доверяю, зная Вас лично, и Ваше целеустремление в СЕО,
во вторых, проверял вручную пару файлов, вроде всё ок,
но всё же не понимая основ алгоритма, другие могут с недоверием отнестись к этому инструменту.
А инструмент, надо сказать очень даже полезен, учитывая его низкую стоимость,
т.к. он может экономить массу времени убивая мусор, пусть даже с 3% ошибок,
а руками % ошибок всё равно будет выше, в разы, проверено)).
позиции/видимость сайта в мобильном поиске
Уважаемая команда рашаналитикс!
Пожалуйста, проведите объективное(можно открытое) исследование,
и если выдача на мобильных сильно отличается,
и если это в принципе нужно отслеживать,
то организуйте съем позиций ещё и с мобильного поиска.
(мы пока что не знаем таких сервисов для съёма, Вы будете первыми))
У нас уже ~50% заходят с мобильных устройств,
причём это зависит от темы/категории, где-то 30, где-то 60%.
Моё виденье, что если сегодня выдача ещё не сильно отличается,
то не факт, что так будет и завтра.
Ведь ПФ, мобильной выдачи может отличатся не только по техническим причинам,
типо того как говорит ув. Сергей К.,
но и даже просто, от того, что мобильная версия сайта визуально может не понравится посетителю, в отличии захода этого же посетителя со стационарного компьютера.
Соответственно, ПС будет развивать алгоритмы ранжирования в мобильном поиске,
ну или как минимум разделять ранги сайтов в этих 2х поисках на выдачи.

Минус-слова - возможность использовать минусовщик Rush Analytics без сбора СЯ
Я думаю, что поскольку у вас уже есть большая база минус-слов по разным направлениям, а многие по привычке пользуются кейколлектором, не плохо было бы иметь возможность за плату минусовать загружаемый список КС.
Сервис поддержки клиентов работает на платформе UserEcho