Форум поддержи Rush Analytics - напишите нам и мы обязательно поможем!

 проверка индексации выдает какой-то странный результат
проверка индексации выдает какой-то странный результат

 Кнопка удалить выбранные проекты не работает
Кнопка удалить выбранные проекты не работает
 Кластарезация без региона
Кластарезация без региона
Выбрал кластеризацию по Яндекс. В поле региона выбрал "--" - я думал что это по умолчанию выдача Вся Россия. Метод был WordStat. Точность 3. - Результата не было, т.е все запросы попали в категорию "не кластеризировано". Получается что для Яндекса обязательно задавать регион? А если хочется по всей России посмотреть?

Баг?! При "кластеризации" не была учтена частотка

У запущенного Wordstat-проекта нельзя посмотреть свойства?
А собственно почему нельзя посмотреть?

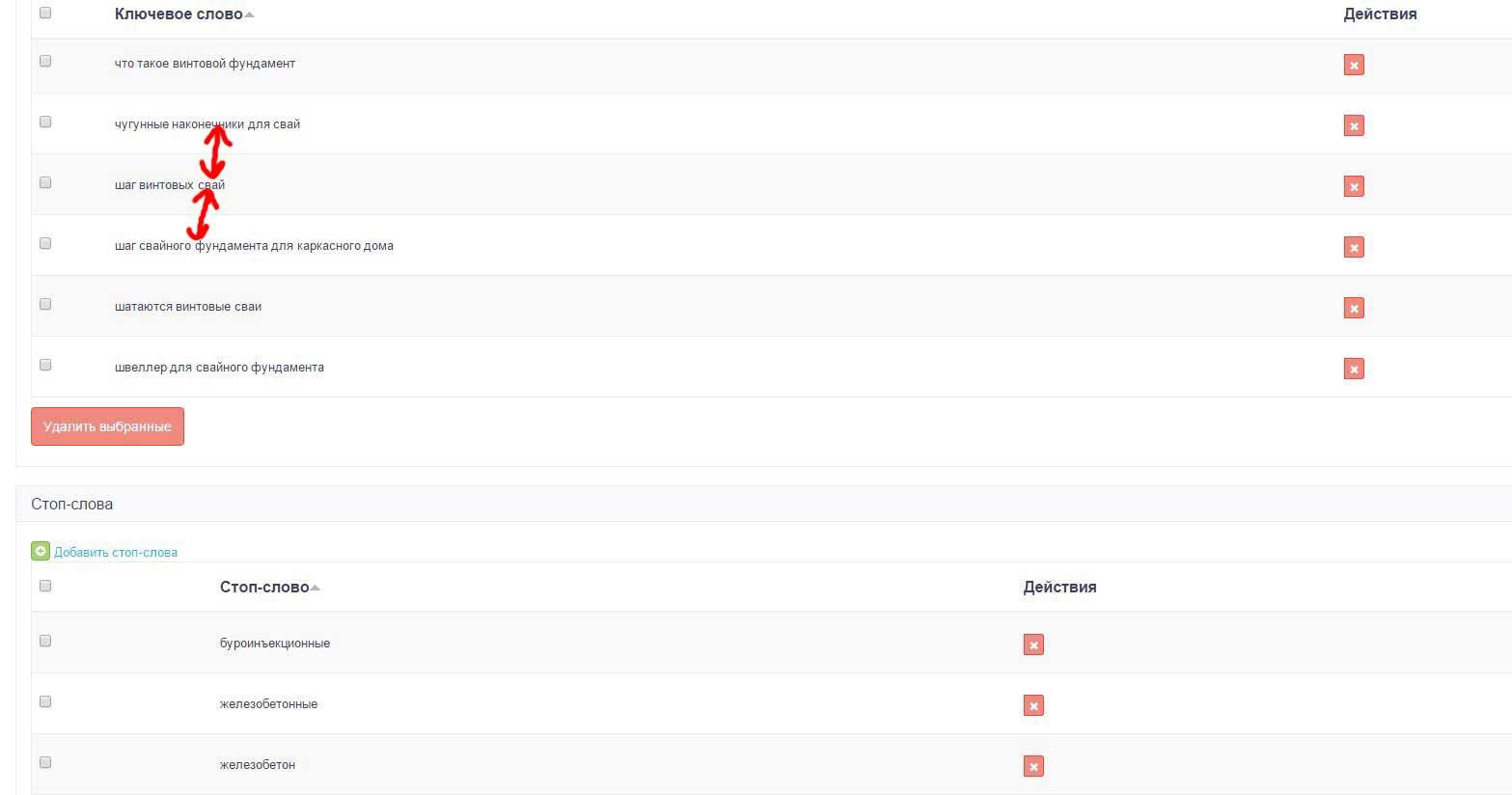
Удаление дубликатов
1. Заметил, что при добавлении повторно слова в "стоп-слова" оно дублируется. Также в самом списке ключевых фраз, после подбора и добавления фраз у меня появилось большое количество дубликатов. Может быть добавить удаление дубликатов в проекте как функцию по кнопке или лучше в автоматическом режиме.
2. Ещё хочу отдельно про дизайн списка в настройках проекта (о вкусах конечно не спорят, просто выражаю свою точку зрения), с ним не очень удобно работать. Он очень громоздкий, большие интервалы между фразами. Плюс список ключевых фраз плавно переходит в список стоп-слов и теряешься. К примеру у меня в одном проекте было порядка 2-3 тысяч слов и из-за этого список не быстро подгружался.
В режиме "Настройки проекта" сделать список таким же, как и в "результаты проекта", только с добавлением кнопки удалить фразу и "стоп-слова" как то отделить от общего списка.
С уважением, Александр.

Регистрация на сайте
Получается, что сразу после регистрации на сайте, для получения пароля нужно воспользоваться формой для его восстановления, что не удобно и как минимум странно.

Проверка ключевых слов - необходима операция над строками, а не над одной ячейкой
Здравствуйте!
Доработайте, пожалуйста, функционал "Проверка ключевых слов".
Технически:
1 вариант
Необходима операция над строками, а не над одной ячейкой.
Т.е. нужно чтобы функция разметки запросов распределяла по вкладкам не только сами запросы из одной ячейки таблицы, а всю строку целиком, ориентируясь на запрос в первой ячейки строки.
2 вариант
Или можно как у вас над сейчас, только чтобы файл с распределёнными запросами, были подставлены соответствующие им данные из исходного файла. Этот способ, даже быстрее будет в работе самой функции.
Сейчас у Вас только сами запросы распределяются на хороший/плохой,
с этим всё отлично! Будем ещё тестировать, но вроде у Вас хороший алгоритм проверки.
Но работать в сегодняшней реализации не удобно.
На входе файл запросов с частоткой, а на выходе получаешь только сами запросы, уже без частотки.
Это не удобно, приходится обратно идти в эксель, далее впр....
и только потом можно загружать файл на кластеризацию.
Я думаю Вам все же стоит стремиться к тому, чтобы как можно больше операций совершали Вашим сервисом, а для этого нужно чтобы везде где возможно, всё передавалось от функции к функции сервиса по конвейеру, без промежутков ввиде выгрузки, работы в эксель и т.п.

Партнёрская программа и безнал
Сервис поддержки клиентов работает на платформе UserEcho


{kind=link}