Ваши комментарии
А что же делать нам сейчас? --
-- фактически мы потратили 12тр в пустую, всего лишь не поставив пару галочек разной точности, как то не серьёзно получается.
Вот пример реального результата JM, и как можно отформатировать даже такие сложные для обычного юзера данные, чтобы с ними можно было работать
ОРИГИНАЛ (отрывок)
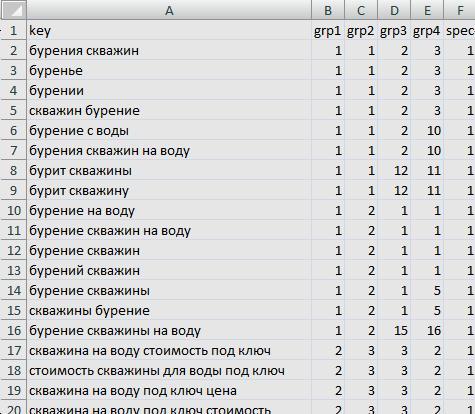
ОТФОРМАТИРОВАНО
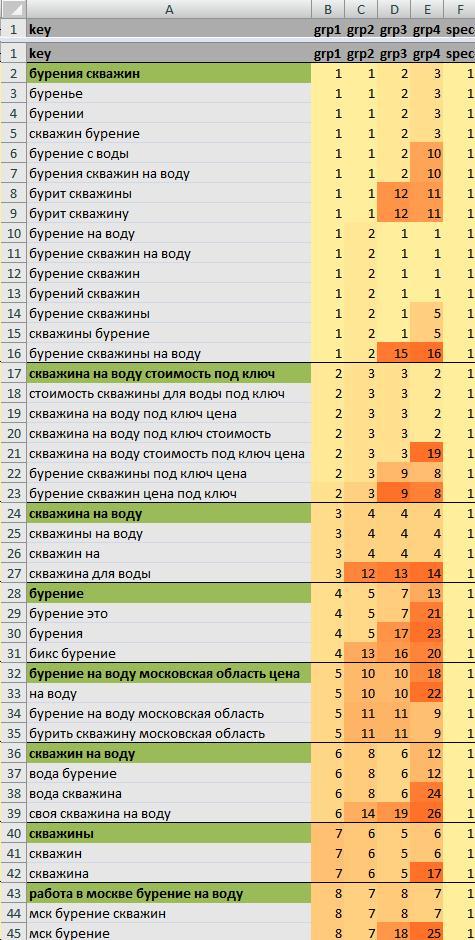
Применил в экселе:
"Условное форматирование" -- "Цветовые шкалы"
и ещё, уже руками,
выделил главные ключи и отчертил над ними верхнюю границу.
Думаю, что всё это скриптами можно разукрашивать на автомате,
больших сложностей для прогера-эксельщика это не вызовет.
Почему считаю мусорными/безполезными/неточными данными?:
1. Размер кластера
2. Суммарная частотность кластера
Приведу примеры результата:
==================================================
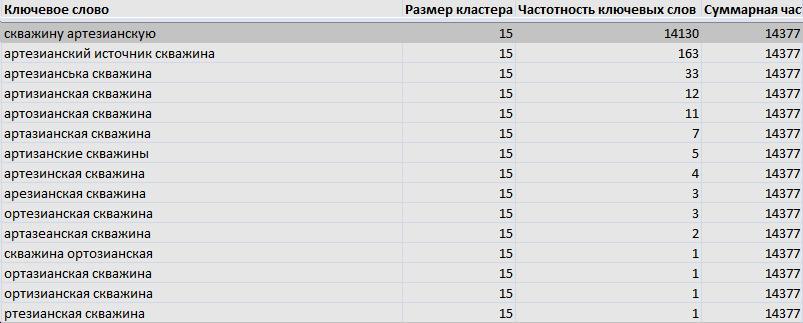
Т.о. бесполезно набегает счётчик "размер кластера"
==================================================

==================================================
==================================================
основные плюсы сегодняшнего отображения результата группировки
1. выявление главного ключа кластера
2. визуальная разбивка кластеров цветом
3. Подсветки для кластерa
4. Лидеры тематики
==================================================
не плюсы, но хорошее дополнение
1. Top URL
2. Название кластера
==================================================
не плюс, не минус, и нет хорошего применения
(а может я не умею работать с СЯ)), но всё же считаю эту информацию излишней, она создаёт перегруженность данными в таблице, затрудняет разбор, приходится каждый раз удалять)
1. Размер кластера
2. Совпадений ТОПа
3. Суммарная частотность кластера
4. Подсветки (думаю было бы достаточно "Подсветки для кластерa")
==================================================
Да, я и сам понимаю, что режим отображения в приведённом примере не всем легко понятен,
можно назвать этот режим "эксперт".
Варианты решения:
1.
попробовать отобразить по другому,
но это нужно прогерам и юзерам генерить идеи,
временной интервал на выполнение этой задачи будет не прогнозируемым,
т.е. идея может придти и завтра и послезавтра, а может через год или три года...
2.
Можно подобный вариант реализовать как дополнительный,
например, на отдельной вкладке "режим эксперт" в результирующем файле.
3.
Можно попробовать ещё и раскрасить эксель, выделить жирным главные ключи и т.п.
PS: просто я сторонник того, что не нужно придумывать велосипед заново,
форм-фактор и принцип велосипеда уже давно придуман, его можно только доработать/модифицировать,
как например, относительно недавно придумали к велосипеду амортизацию заднего колеса,
это очень увеличило комфорт, взяли с авто дисковые тормоза.
Ведь за дисковые тормоза автопроизводители не ругают же велоделов, что мол сдули у них)), да и принцип дисковых тормозов тоже другой придумать невозможно, можно опять таки, только доработать/модифицировать, или придумать систему торможения с нуля, а это опять таки генерить идеи, и не факт что смогут придумать что-то приемлемое на практике.
Ребята из JM молодцы, придумали принцип отображения ключей сгруппированных с разной точностью,
теперь это как один из листов в библиотеке знаний по СЯ.
Здравствуйте, Олег!
Да, я тоже уже давно задумывался, над тем,
что многие снимаю выдачу по регионам, а вот про "регионы отдельного государства Москва"))) никто не замарачивается, хотя для не малого количества сервисов, было бы очень даже полезно отслеживать/продвигаться по топонимам не только МО, но и Москвы.
Для нашего сайта всё равно, во всяком случае сегодня мы работаем над гео-сео по МО,
но в обозримом будущем, вполне себе вероятно продвижение по гео-названиям Москвы.
Я голосую ЗА съём по гео-названиям Москвы, хотя бы по официальные, но если возможно дополните станциями метро, которые в ряде случаев названия отличаются разительно от админ.районов.
Можно же потом прикрутить гео, сейчас бы мне было очень даже интересно посмотреть просто выдачу мобильного поиска))).
Да, Олег, именно так.
Хранить или потом дописывать, это как будет удобнее.
Главное прикрутите алгоритм к кластерезатору)),
а потом уже добавьте чек-боксы в интерфейсе и алгоритме:
◘ по кластерам
◘ по запросам
◘ по слова
Цена одна, за проверяемую единицу,
кто хочет платит за клатстеры,
кто хочет тотальную проверку, платит за каждое слово,
просто по словам проверяемых единиц будет больше, соответственно и цена выше,
а Вы ничего не теряете, зато даёте юзерам выбор.
Я так понимаю что основная функция в алгоритме - одна,
просто аргументы для неё будут разными.
Да, это будет здорово!
Вчера вот только думали над задачей полной разметки всей собираемой семантики на ком/инфо запросы.
Хорошо, пусть будет в функционале кластерезатора,
я так и понимаю, что так и так нужно серпы собирать,
т.е. цена бы по-любому была одна.
Олег, а как скоро можно будет увидеть эту функцию?
Сервис поддержки клиентов работает на платформе UserEcho

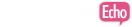
вот это как раз то:
"плата раньше бралась только за 1 вариант в котором было кластеризованно больше всего запросов"
и ввело в заблуждение семантика, он выбирая точность 8, типо самую-самую, по человеческой логике предполагалось ожидать, что остальные частотности как само-собой соберутся))), ан нет.
Нет, не могу винить Вас, больше всё же мы сами виноваты, не внимательно читали..., но честно сказать не сразу понятно... Пока раз-два не соберёшь, сразу и непонятно как всё работает, и да, и неожиданно, на выходе получить кучу файлов, ожидался один файл со всеми точностями)) (я уже об этом писал ранее)
==================================================
Жаль что не храните серпы, так бы такие(и другие, типо добавление запросов) проблемы бы не возникали...
Тема уже обсуждалась, и Вы говорите что исправлять баги дорого... ну Вам виднее, ничего не могу сказать.
==================================================
Спасибо, что вызываетесь помочь,
(я тоже уже не мало Вам помог увидеть сервис со стороны юзера, но я эту помощь тоже оказывал ради помощи в создания хорошего сервиса по сбору СЯ )
и мы тоже в данной ситуации немного можем пойти навстречу,
мы уже очень сильно почистили ключи из этой темы, которая несгруппировалась,
и теперь уже на 20% меньше ключей в этой теме))
за этот проект мы заплатили 12744, теперь он стоит 10523,
но как теперь поступить? прислать Вам файл с меньшим кол-вом запросов, или создать новый проект? (эээ... создать новый проект не получается ввиду недостатка баланса)