- Форум поддержки Rush Analytics
-
 Вопросы
Вопросы

0
Отвечен
Вопрос по итоговому файлу парсинга подсказок и вордстата
После парсинга поисковых подсказок, при глубине 3, результаты в файле xls выдаются в четырех колонках, в итоге большую часть из ключей приходится удалять (поскольку это дубли). При большом количестве ключей это не очень удобно. Это можно поправить или так и должно быть?
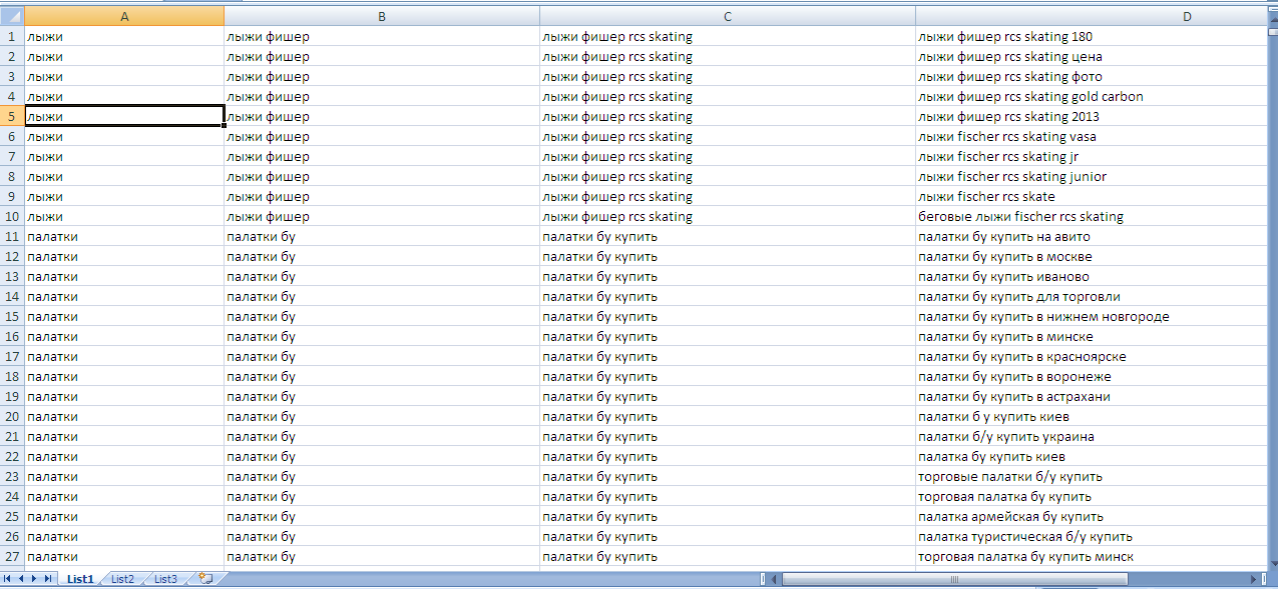
Второй вопрос по парсингу вордстата: когда ввел десяток ВЧ в разделе wordstat, на выходе получил просто их частотности. То есть, для получения данных из левой колонки wordstat следует вводить сугубо по одному ключу?
Второй вопрос по парсингу вордстата: когда ввел десяток ВЧ в разделе wordstat, на выходе получил просто их частотности. То есть, для получения данных из левой колонки wordstat следует вводить сугубо по одному ключу?
Сервис поддержки клиентов работает на платформе UserEcho
По сбору подсказок.
Дело в том, что в первом листе отображаются абсолютно все подсказки. А так как некоторые слова могут порождать одинаковые подсказки, то и получается много повторений.
Во втором листе файла собранны все подсказки уже без дублей.
По вордстату.
На выходе – частотность, если у вас в настройках указанно «сбор частотности»
Для того, что бы получить данные из левой колонки нужно в настройках проекта указать «Сбор ключевых слов из левой колонки Wordstat” Ключи собираются сразу все.